A Cinematic Trailer Pipeline: Draft on Seedance, Deliver on HappyHorse
Trailers are a two budget problem. First, exploration: how the camera moves, what the pace feels like, what order shots land.
Trailers are a two budget problem. First, exploration: how the camera moves, what the pace feels like, what order shots land. Second, final hero frames. Spend both on one model and you overspend on drafts or under deliver on masters. The cleaner pattern: split the pipeline by stage, route the right work to the right model, and keep the prompt stable between them.
Stage one drafts on Seedance 2.0 at 720p. Stage two finals on HappyHorse 1.0 at 1080p (Seedance fallback until the HappyHorse endpoint lands). The payoff: a minute of trailer content, 8 hero clips, 30 drafts, for about $4.35 pre tax.
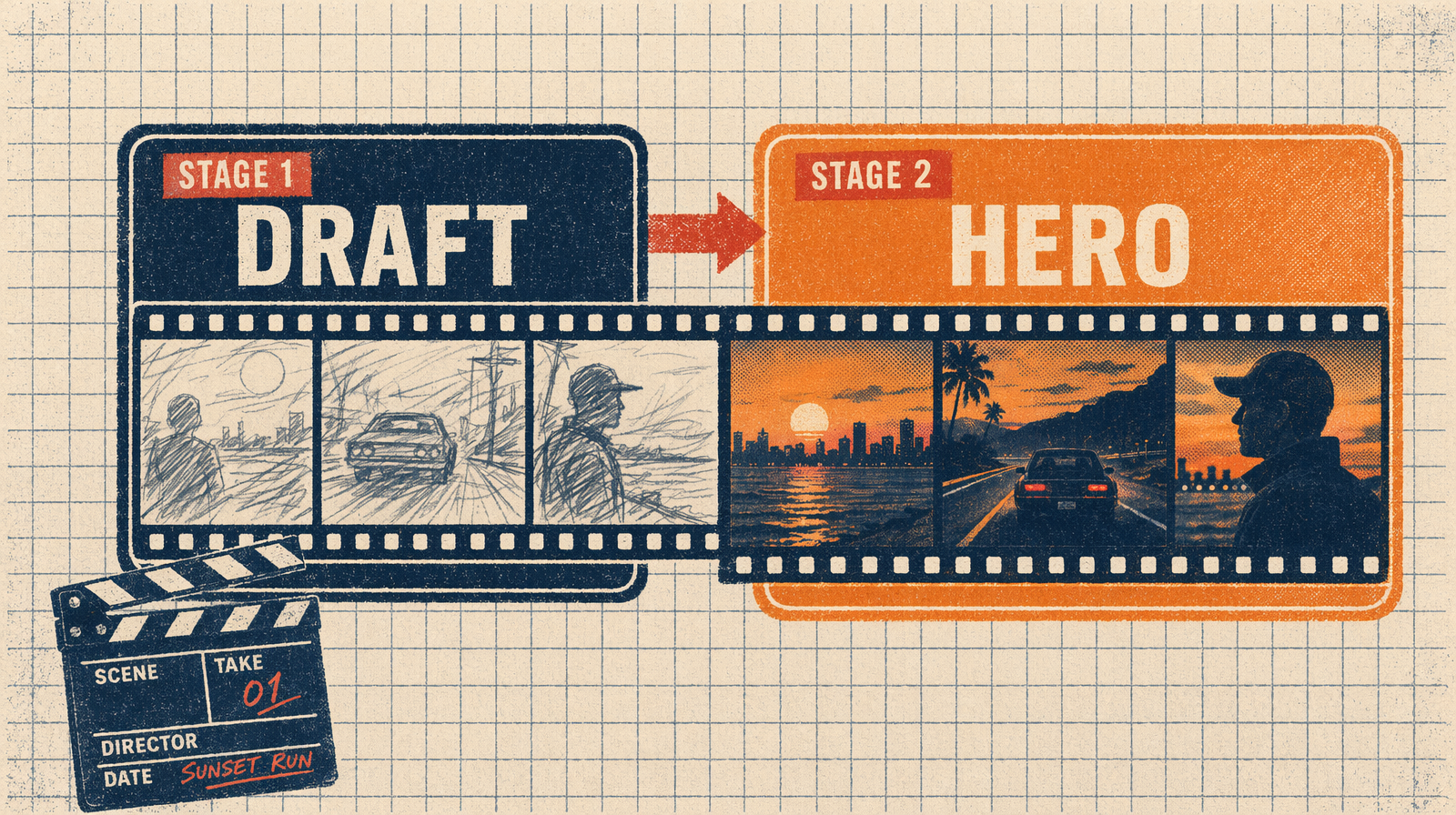
Why two stages
The worst thing you can do with a video model is treat every render as a hero. The second worst is to draft so low you cannot read camera language, so finals turn into first drafts.
- 720p drafts are readable enough to lock camera movement, pacing, cut order, and framing.
- 1080p finals earn their cost because every parameter except resolution has already been nailed.
Seedance 2.0 is the draft engine at about $0.014 per unit, $0.07 for a 5 second 720p clip. HappyHorse 1.0 is the delivery engine when you need lip sync and native audio. On visuals only, Seedance 2.0 at 1080p is a fine stand-in until the HappyHorse public endpoint opens.
Stage one: the draft run
Your prompt carries three blocks: a style prefix, a shot block that changes per take, and a resolution knob at 720p.
1import { fal } from "@fal-ai/client";23const STYLE = "late afternoon gold, 35mm grain, muted orange and teal, handheld, shallow depth, anamorphic flares";45async function draft(shot) {6 return fal.subscribe("fal-ai/seedance-2.0/text-to-video", {7 input: {8 prompt: `${STYLE} ${shot.description}`,9 resolution: "720p",10 duration: shot.seconds ?? 5,11 aspect_ratio: "2.39:1"12 },13 logs: true14 });15}
Thirty of those at 5 seconds each runs 30 * $0.07 = $2.10. Order them into a rough cut, mark 8 survivors. For a one minute trailer, aim for 18 to 24 cuts. Pick 8 hero beats for 1080p, fill the rest from drafts (a grade pass hides 720p inside a 1080p cut).
Stage two: the hero run
You have 8 hero beats. Switch to HappyHorse (or Seedance fallback), flip resolution to 1080p, and let the audio render if the beat has dialogue.
1async function hero(shot) {2 return fal.subscribe("fal-ai/seedance-2.0/text-to-video", {3 // or fal-ai/happyhorse/v1/text-to-video once available4 input: {5 prompt: `${STYLE} ${shot.description}`,6 resolution: "1080p",7 duration: shot.seconds ?? 58 },9 logs: true10 });11}
Only the model id and resolution changed. You are not re prompting, you are re rendering.
At Seedance 1080p (about $0.28 per hero clip), 8 heroes run $2.24. Plus $2.10 drafts, you are at $4.34. Call it $4.35 per trailer minute pre tax. At a 2x HappyHorse premium, you stay under $7.
The prompt that gets reused
Too many pipelines rewrite the prompt every stage and wonder why the hero does not match the draft. Bake the prompt as one string with a resolution variable outside it.
1const PROMPT = [2 "late afternoon gold, 35mm grain, muted orange and teal,",3 "young rider on a bay horse cresting a dune,",4 "slow 3 second push in, wide to medium, no cut"5].join(" ");67async function render(modelId, resolution) {8 return fal.subscribe(modelId, {9 input: { prompt: PROMPT, resolution, duration: 5 },10 logs: true11 });12}1314// draft15await render("fal-ai/seedance-2.0/text-to-video", "720p");16// hero (or fal-ai/happyhorse/v1/text-to-video once available)17await render("fal-ai/seedance-2.0/text-to-video", "1080p");
Same prompt, two rails. The hero is an up rez, not a reinterpretation.
Budget math
| Stage | Count | Cost per | Subtotal |
|---|---|---|---|
| Draft (Seedance 720p, 5s) | 30 | $0.07 | $2.10 |
| Hero (Seedance 1080p, 5s) | 8 | ~$0.28 | $2.24 |
| Total per trailer minute | **~$4.34** |
Three rules. Freeze the style prefix across the trailer. Draft at 720p. Track prompt, resolution, and model id per take so a client tweak to shot 5 reruns exactly shot 5.